GLM-5.2 是开放智能体领域的跨越式升级
一个我一直在密切关注的能力门槛。
重要说明:继上周我发布“博客现状”一文(提到付费功能略有增加)之后,现在正好提醒大家,我提供团体订阅服务,折扣幅度随席位数量递增。此外,我今天还发布了一篇关于终端智能体开源强化学习方案的新论文,更多详情请点击此处阅读。
大约一周多前,当 AI 界还沉浸在 Claude Fable 5 遭遇惊人出口限制(事实上等同于被禁)的震惊中时,Z.ai 发布了他们的最新模型 GLM-5.2。该模型于 6 月 13 日(星期六)异常地先行向 GLM 编程计划成员推出。这是一种不同寻常的发版做法——通常情况下,AI 模型在周末发布往往是因为某种奇怪的原因(最著名的例子是 Llama 4)。① 在此案例中,Z.ai 似乎是想借“Anthropic 反开放科学”(他们对 AI 研究人员实施沉默式安全管控)的舆论风潮来抢占先机。过去一两年里,中国开源权重实验室每逢此类机会都会毫不犹豫地借势营销,轻松赢得市场关注。
GLM-5.2,按照业界常见的命名惯例,看起来像是继广受欢迎的 GLM-5.1 之后的一次增量更新。时至今日,月之暗面(Kimi 模型的开发商)和 Z.ai(GLM 模型的开发商)已经巩固了口碑市场的前列地位,成为 AI 研究人员中最受喜爱的开源权重模型厂商。而接下来发生的事,则再次印证了追踪 AI 模型时的一个常见经验:看似微小的版本号变化,有时却能让 AI 模型跨越意义重大的用户体验门槛。基准测试和训练上的小改动,足以打开一整套全新的应用场景。
随之而来的,是围绕 GLM-5.2 缓慢积累的炒作浪潮。官方在初始发布三天后,也就是 6 月 16 日,放出了 MIT 许可的模型权重和发布博客。或许可以赘述很多技术细节,例如亮眼的基准测试分数、智谱(Z.ai)使用的非常流行的强化学习框架(SLIME),以及始终建议在 Max 思考强度下使用该模型等等,但初期的发布博客通常不是关注的重点。你可以静观整个生态系统的反响,来判断它是否真的货真价实。反正如今,基准测试已经半死不活了。
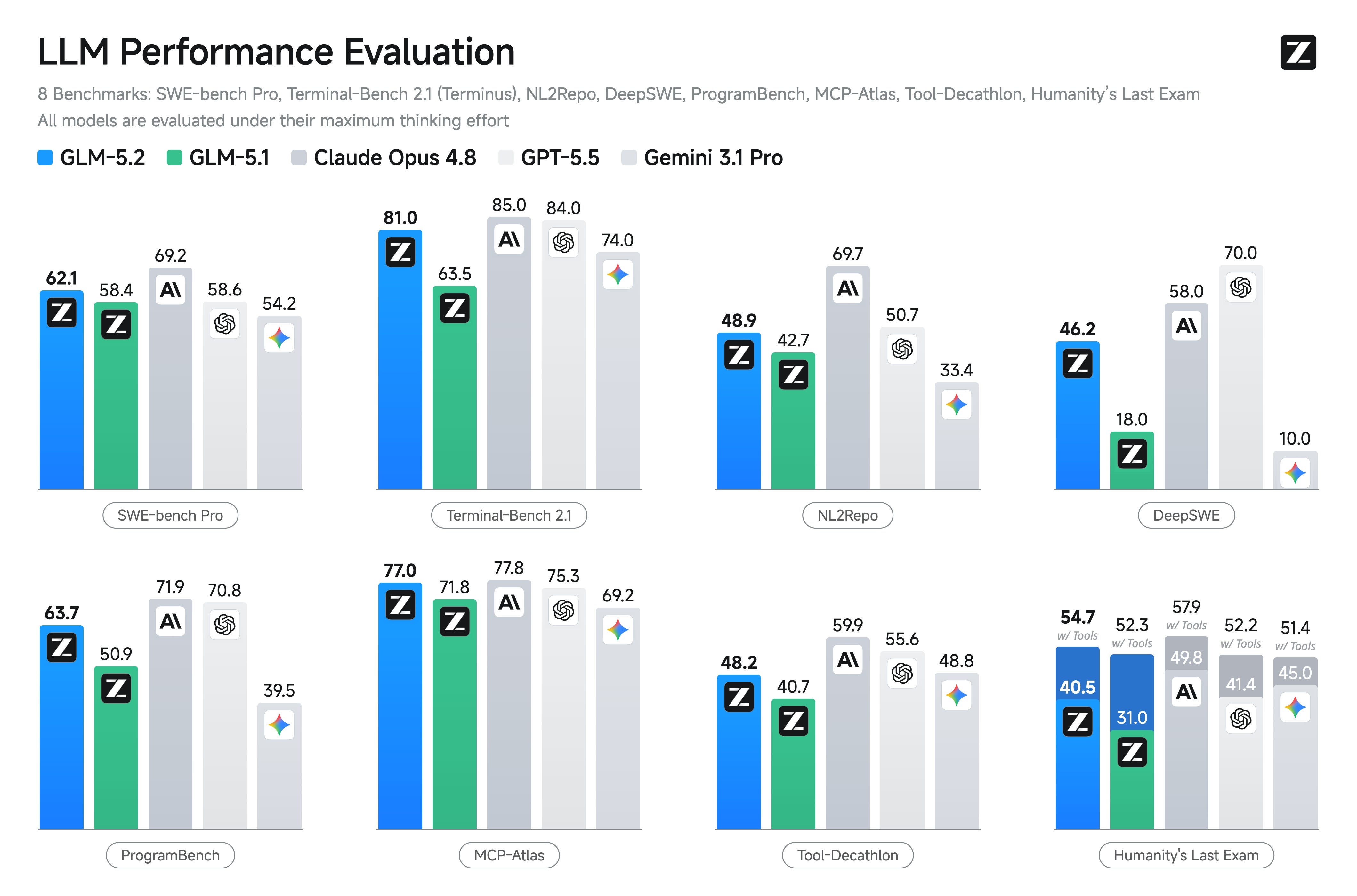
随后在 16 日,涌现了大量社区基准测试,结果显示 GLM-5.2 的表现超出预期。在 Chatbot Arena 的智能体排行榜上,它是唯一能与 OpenAI 和 Anthropic 最新模型一较高下的开放模型(值得注意的是,其无思考模式下的表现与 Opus 4.8 持平,而 GLM-5.2 则使用了最高模式)。这是 GLM-5.2 在众多评测中碾压 Gemini 的案例之一,不过这得另找时间再谈。在一个社区(尤其是实际设计者)看法褒贬不一的基准测试——Design Arena 中,GLM-5.2 甚至击败了 Claude Fable 本身——这个最近被禁言的炒作机器!
在我尊重的 AI 评论界和研究人员中,几乎所有人亲身体验后都称赞了该模型。社区中此前的讨论焦点,在开放模型发布中如此明确的情况,只出现过一次——那便是 DeepSeek R1。这个比较并非轻率之举,此前我将 Kimi K2 的发布比作“DeepSeek 时刻”,而 GLM-5.2 的表现远超那次。Kimi K2 的令人印象深刻之处在于,开放模型性能的巨大飞跃似乎可以来自中国的任何地方。而 GLM-5.2 所迈出的这一步,更像是 AI 进步的一扇单向门。
Anthropic 凭借 Claude Code 实现的创纪录收入增长率,很大程度上源于它是当前最优秀的模型,也是唯一真正能胜任这项工作的模型。GLM-5.2 则是众多即将推出的开源权重模型中第一个提供可靠替代方案的。两者之间的平行关系非常清晰——正如 DeepSeek R1 曾证明的那样,资源远逊于 OpenAI 的开源权重实验室同样能够复现 OpenAI 以 o1 为代表的链式思维推理模型。随着 AI 系统日趋复杂、构建成本急剧攀升(涉及工具、集成框架和扩展的模型权重),GLM-5.2 这个时刻能否到来,原本并非必然。
关键在于,GLM-5.2 是一款在编程框架中作为通用智能体使用时感觉恰到好处的开源权重模型。它是第一个。我个人早就该尝试一些近期同类模型,比如 Kimi K2.7 或 GLM-5.1,但相关的热度实在让我无法忽视。我让它帮我在 Claude Code 中(通过 Fireworks 的 API)制作课后培训课程的内容——设置起来非常方便。过程中有一些小磕绊,比如 Claude Code 框架/我的仓库文档试图向模型发送图片,这会导致 Fireworks API 在当前会话中失效——不得不手动清除上下文。总体而言,模型的能力立刻给人感觉对劲,我还在琢磨该使用哪个框架和推理提供商。
更多热度可以看看:Z.ai 创始人告诉 Elon,“开源权重的 Fable 能力将在 2027 年第一季度之前到来”;Vercel 的 CEO 表示“@zai_org 的 GLM-5.2 在编程方面的表现好得令人印象深刻,几乎让我震惊。这改变了局面。”还有来自其他一些人的大量评论——其中既有我深表尊敬的观点,也有我尚不熟悉的看法。
总之,这是一款好模型。那么这给我们留下了什么?
当前有多种趋势在同时发挥作用。首先,让我们从开源与闭源能力差距的角度来切入。我曾撰文表示,如果开源模型能够在 Claude Code 中达到 Opus 4.5 的门槛,预计从 2026 年初左右开始,“使用量将出现爆炸式增长”。如今这一时刻已经到来。Claude Opus 4.5 于 2025 年 11 月 24 日发布,而 GLM-5.2 于 2026 年 6 月 16 日发布,两者之间的时间差为 204 天——约 6.8 个月。这恰好落在许多人声称的美国闭源实验室与中国开源对应方之间存在 6-9 个月性能差距的时间范围内。
写下这些时,我感到意外。在过去大约一年里,美国实验室的算力投入增长速度极快,我原本预期性能差距会随时间进一步拉大。在这一发展轨迹中,一个非常有意义的节点将是 Claude Fable 5 的发布——与 Claude Opus 系列模型相比,它更依赖于规模扩展,因此也需要最先进的 GPU。不过,这并非一个令人满意的答案。要继续深入拆解这条发展轨迹,需要涉及的细节比我在这篇路标式文章中所能容纳的要多得多。
这一局面最直接的意义在于,那些致力于 token 最大化的组织内部将面临更加严峻的定价压力,从而推动 Anthropic 的收入一路飙升。有人可能会预测 Anthropic 无法实现其预测的 ARR 数字,但我不认为当前价格反映了这些模型的真实需求以及必然的增长。该模型的存在对开源模型经济是一个巨大的利好。所有像 Fireworks、Together、Thinky(通过 Tinker)、Prime Intellect 以及其他任何销售开源模型推理或微调服务的厂商,都刚刚迎来了另一个拐点。
这些影响要渗透到更广泛的经济领域和应用场景中,还需要很长时间。工作流程正变得愈发复杂,人们开始用不同的模型分别负责规划、主要编码以及子智能体分派。我预计这股热潮还会继续升温,而且,嘿,就在我写这篇文章的周日晚上,我已经能预见周一媒体和市场的反应会像 DeepSeek R1 发布时一样轰动。在 Anthropic 的旗舰模型——也就是美国方面的旗舰模型——仍被禁用的背景下,这种渗透扩散无异于一把刺向经济命脉的匕首。GLM-5.2 正趁着前沿实验室想向更高利润、更高收入领域(只有绝对前沿的模型才能实现)推进的当口,抓紧时间从它们的经济腹地中切下一块。
这种经济层面的担忧,与 AI 领域反复上演过多次的故事如出一辙,因此目前还不清楚它何时会真正引起重视。
在我看来,更关乎 AI 发展轨迹的对话,是关于开放模型的监管与控制。我认为,廉价智能的广泛扩散是一件经济上的好事,我们的默认立场应该是为开放模型喝彩。但这款模型的发布时间,会让它在 AI 权力格局的心智地图上,永远与 Claude Fable 挂钩——进而与 Claude Mythos 联系在一起。我们现在正处在一个节点上:美国政府对 Mythos 级别的模型能力判定为不宜公开发布,而中国的模型厂商却在人人可用的能力上不断推进。
这些趋势线之间未必存在因果关系,因为我们不清楚 GLM-5.2 与其前代相比在网络安全方面的具体表现,但能力之间肯定是相关的。如果一切照旧,这就指向一种可能性:美国政府可能会判定某个中国开源权重模型对公众不安全。当然,这里还有很多其他潜在情景,但显而易见的是,我们在梳理这些情景、准备相关基础设施以及向社会传达信息方面,还有很多工作要做。
要让决策者理解并构想出一个如何管理能力日益强大的开源模型的世界,仅靠我一个人是远远不够的。在英伟达下一代芯片已投入生产、算法也在不断进步的情况下,我们还有数年的AI发展进程。对于开源模型的支持者而言,这似乎是一条狭窄的道路,但我们必须找到让它们可行的办法,确保性能的巨大飞跃不会仅仅局限于闭源模型。
我完全理解,想象一个可公开访问的“Mythos”级别的模型确实令人担忧,但如果现在开源模型被禁止,而只有一两家公司在两年内将闭源模型的能力提升10倍甚至100倍,我认为届时我们将面临更大的问题。
一直让我印象深刻的是中国实验室发布模型的速度。我从多个实验室了解到,从模型训练完成到将权重公开上传至 HuggingFace,所需时间可以以小时计,而非以天计。现在这种情况至少有所放缓,因为它们还需要准备为更广泛的推理市场提供服务。
未来需要更多讨论的一点是,即使是闭源模型,例如“Mythos preview”,也时常被未授权用户获取或遭到越狱。因此,在访问权方面,开源与闭源的二分法并非完全非黑即白。