Artifacts 22:Zyphra、Cohere 和 Poolside 正在扩展生态系统广度
阅读原文· interconnects.ai这篇文章把开源模型玩家拆成三类,清晰解释了不同动机,Cohere 转向 Apache 2.0 和 NVIDIA 采用 OpenMDW 是许可层面的重要信号,关注开源的值得一读。
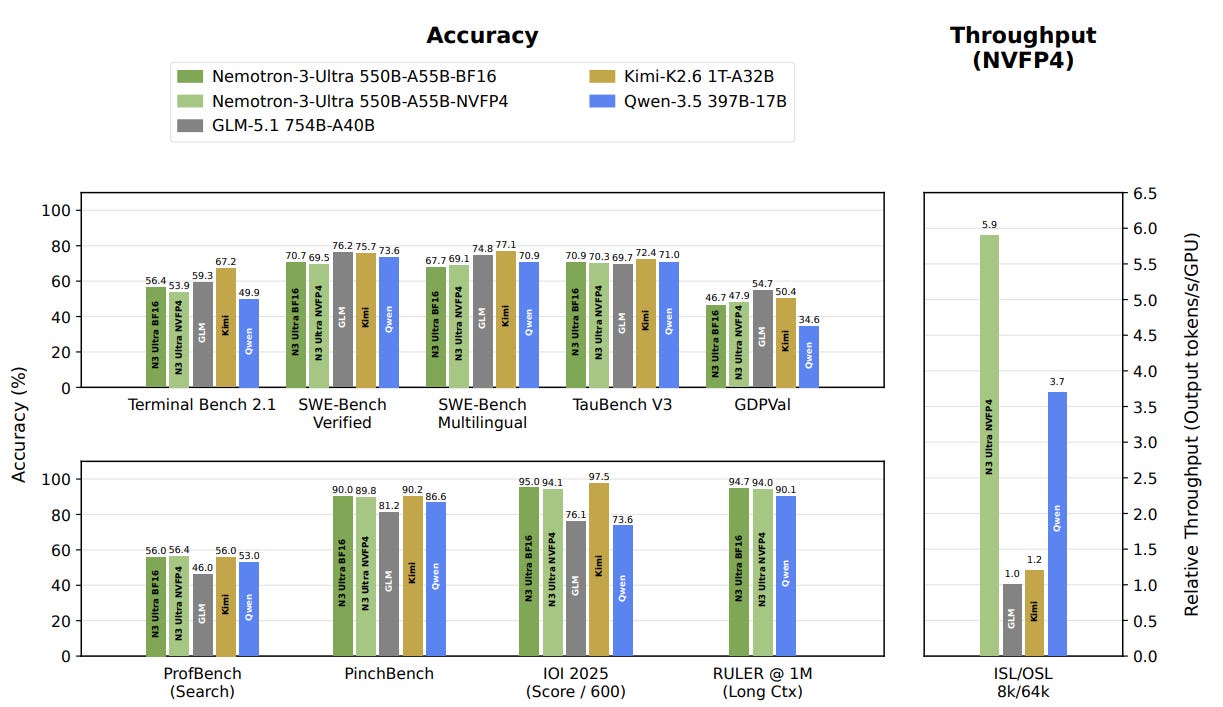
开源模型生态正变得更多元,参与者从少数中国公司扩展到全球各类组织。纯模型制造商包括 DeepSeek、智谱、MiniMax、Poolside、Arcee、Zyphra 及主权 AI 玩家 Cohere、Sovereign、Mistral、Trillion Labs;科技巨头如阿里 Qwen、Google Gemma 和 NVIDIA 各有不同动机;产品公司如 JetBrains、Zed、Krea、Photoroom 则训练高度专业的小模型。NVIDIA 发布 Nemotron-3-Ultra-550B-A55B-BF16,采用 LatentMoE 架构并改用 OpenMDW 许可证。Cohere 以 Apache 2.0 开源其旗舰模型 Command A+(05-2026-bf16),这是一款 218B-A25B MoE 模型,具备多模态、多语言和智能体能力。
第22期“人工制品”:Zyphra、Cohere和Poolside正拓展生态系统的广度
对开放生态系统及模型发布背后动机的评估
我们在开放模型发布中持续观察到的一个趋势是:生态系统正变得更加多元化,越来越多的组织发布了种类繁多的模型。一年前,开放“人工制品”以及更广泛的开放模型领域还被少数(中国)玩家主导。如今这一格局已经改变,我们越来越多地报道世界各地更加细分的公司。
虽然很难确切了解这些公司自身的动机,但我们可以大致观察到以下几类:
“纯”模型制造商:这些公司的公开目标是在前沿(或至少接近前沿)训练模型。这包括许多中国公司,如DeepSeek、智谱和MiniMax,也包括西方公司如Poolside、Arcee和Zyphra。此外,主权AI玩家也越来越多,例如Cohere、Sovereign、Mistral和Trillion Labs。最近的Mythos事件唤醒了一些政策制定者,这可能会使人们对主权模型训练的兴趣增加。
大型科技公司:对于大型科技公司(包括阿里巴巴的通义千问、谷歌的Gemma,以及在某种程度上英伟达)而言,动机更加多样。阿里巴巴通过发布模型来推销其闭源模型,而英伟达则受益于蓬勃发展的开放模型生态,因为这增加了对其GPU的兴趣和使用。这种既得利益不同于Llama时代的西方开放模型——当时开放发布的动机并不明确(最终也未能持续)。
产品公司:有些公司(如JetBrains、Zed、Krea和Photoroom)主要销售以AI为核心组件的产品。由于它们不希望被切断访问闭源模型的途径,或者希望提供独特的功能,它们可以训练高度专业化的小型模型来满足产品需求。因此,将这些模型权重开源并不会损害它们的利润底线。
这种制造者和模型的多样性符合我们的假设,即会有更多公司开发长尾模型,而追逐绝对开放前沿的公司数量将会减少。
尽管并非每个模型发布都能 neatly 归入这些类别之一,但更广泛的观点是,开放模型的开发并非由单一类型的参与者或动机驱动。这种多样性是开放生态系统的优势之一,并且可以从模型发布的技术报告中看出,这些报告复用了其他开放模型发布中的训练方法、架构选择和数据。
试图放缓或禁止这一生态系统的努力不仅是徒劳的(正如技术相关禁令的历史所显示的那样),而且是不安全且反自由的。此类限制会将 AI 开发和使用集中在少数人手中,最终危及局外人自由采用我们这一代最重要的技术之一的能力。
我们的推荐
NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16 by nvidia:Nemotron 系列的大版本,使用 LatentMoE 使其比同类模型更快。与其他 Nemotron 模型一样,绝大多数数据都是开源的。而且,最重要的是:NVIDIA 承诺使用 OpenMDW 许可证,该许可证专门针对模型权重(及数据)而定,并放弃了其自定义许可证。虽然 MIT 和 Apache 与 OpenMDW 精神相同,但只有后者真正涵盖了模型权重,而前者是软件许可证,并不真正适用于模型权重。

command-a-plus-05-2026-bf16 by CohereLabs:Cohere(近来越来越频繁地出现在 Artifacts 中)发布了其旗舰模型 Command A+,采用 Apache 2.0 许可证。该系列之前的版本是在非商业许可证下发布的,因此这一变化非常受欢迎!Command A+ 以 218B-A25B MoE 的架构结合了多模态、多语言和智能体能力,使其可以在单个 B200 上使用(使用 4-bit 时)。
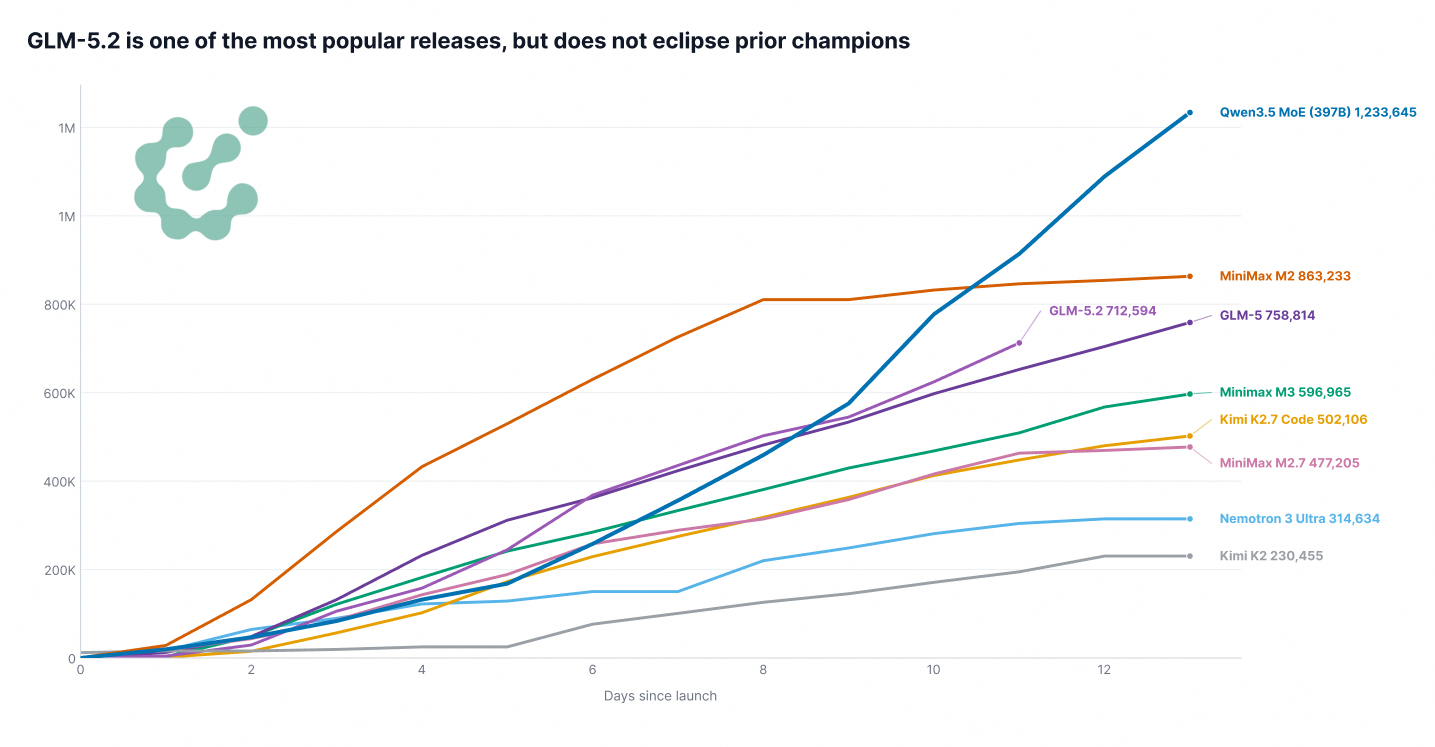
来自 zai-org 的 GLM-5.2:本期 Artifacts 中最重磅的消息是 GLM-5.2,我们在另一篇博客中也已报道过。这个模型持续让人印象深刻,确实可用于日常工作;与当前最优秀的闭源模型相比,并没有明显的倒退。有趣的是,自发布以来的原始下载量与其他模型发布的数据更趋一致,GLM-5.2 在发布后大致与 GLM-5 处于同一水平。

来自 Zyphra 的 ZAYA1-74B-preview:Zyphra 使用 AMD GPU 进行训练,因其技术报告中采用了有趣的架构选择,在研究社区中被视为某种内部消息来源。他们发布了一些新模型,其中 74B-A4B MoE 和 8B-A0.6B MoE(有技术报告)是其当前旗舰版本。
来自 poolside 的 Laguna-M.1:我们在上一期 Artifacts 中报道过的 Poolside,也在 Apache 2.0 许可下发布了他们的旗舰模型!他们还承诺未来将继续进行开放发布:
开放权重现在是我们的默认选项。我们将继续朝着前沿方向努力,并公开发布越来越强大的模型。
模型
通用目的
来自 moonshotai 的 Kimi-K2.7-Code:这是 Kimi 的一次更新,重点专注在模型 token 效率上。
来自 stepfun-ai 的 Step-3.7-Flash:这是 Step-Flash 的更新版本,尤其在数学方面非常强大。
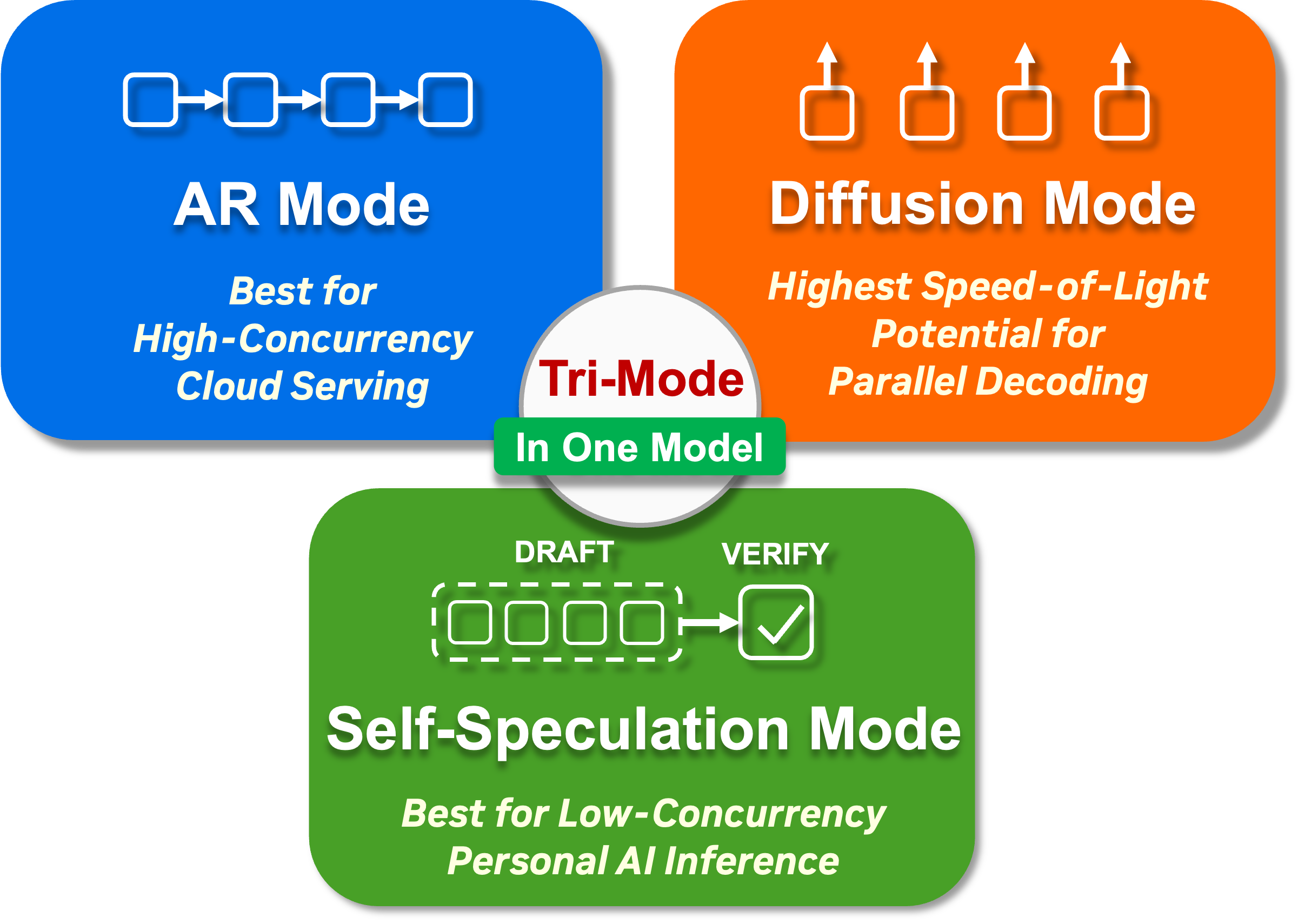
来自 nvidia 的 Nemotron-Labs-Diffusion-14B:这是一个实验性模型,可以通过三种不同模式使用:自回归、扩散和自推测。每种模式适用于不同的使用场景。
